Swarm Development¶
Introduction¶
In the Manta platform, Swarm development allows users to create decentralized and collaborative algorithms that are distributed across multiple nodes. A Swarm consists of various tasks defined by the user, which are executed collaboratively on nodes. The Manta Core provides the necessary tools and abstractions to develop, deploy, and monitor these Swarms efficiently, enabling seamless execution of complex, distributed workflows.
What is a Swarm?¶
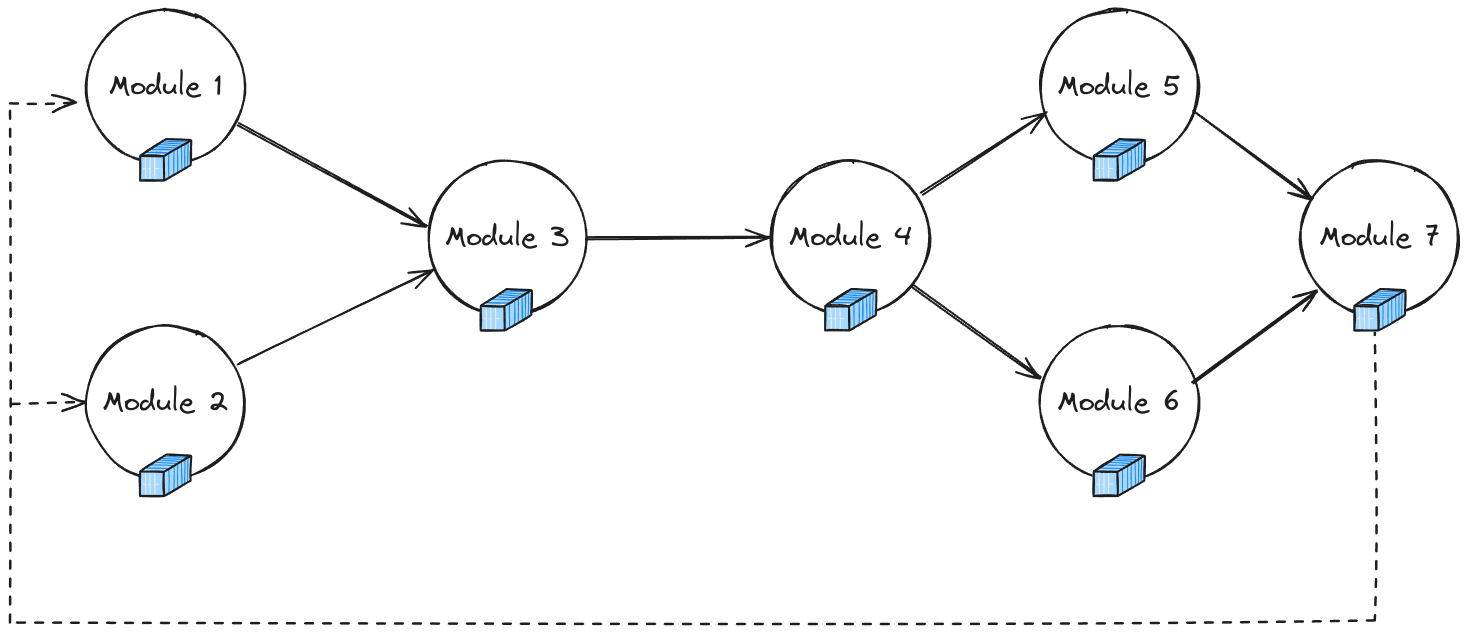
A Swarm is a decentralized pipeline composed of interconnected tasks that execute collaboratively across nodes in a distributed system. Each swarm defines a sequence of operations, organized as tasks, that collectively perform a larger algorithm. The primary feature of a Swarm is its ability to define an iteration that repeats until a specific condition or completion criteria are met. This iterative approach allows for continuous data processing and refinement across multiple stages.
Components of a Swarm:
Tasks: The basic building blocks of a Swarm, each task performs a specific operation or computation. Tasks can depend on each other, allowing complex workflows to be built.
Dependencies: Tasks within a Swarm can be interconnected through defined dependencies, creating a directed graph of operations. These dependencies control the flow of data and execution order among tasks.
Iteration Cycle: A Swarm is designed to operate in cycles, where the defined tasks are executed repeatedly until the Swarm completes its objective.
How Swarms Work¶
Swarms work by defining an iterative workflow that is distributed across multiple nodes. In each iteration, tasks process data, communicate with other tasks, and contribute to the overall progress of the Swarm. This setup is particularly useful for collaborative algorithms, where nodes must work together to achieve a shared goal.
The above diagram illustrates a Swarm consisting of four tasks distributed across nodes. The tasks communicate with each other to pass data and synchronize their operations. After completing one cycle, the Swarm proceeds to the next iteration until it reaches the termination condition.
Swarm Class¶
To create a new Swarm, you define a Python class that inherits from the manta.swarm.Swarm base class. This custom class specifies the tasks, their dependencies, and the overall structure of the decentralized algorithm.
For more detailed information on implementing a Swarm class, refer to the Swarm API Documentation.
Module Class¶
Module defines a task within the Swarm and serves as the building block of any decentralized algorithm.
Each module represents an individual task that operates independently, performing computations based on the node’s local data and contributing to the overall Swarm process.
Modules are executed within container environments, enabling isolated, reproducible, and scalable deployments across heterogeneous devices, from high-powered servers to edge devices.
Core Features of a Module:
Containerized Execution: Each module specifies a container image (e.g., Docker) that encapsulates the task environment, ensuring consistency across different nodes.
Task Independence: Modules are self-contained, which means they can operate without dependencies on other modules except for defined communication or data exchange paths.
Creating a Module:
To define a module, you create an instance of the Module class, specifying the script or the set of scripts that form the task, the container environment, and various execution parameters.
Below is an example of defining a Module:
from manta.module import Module
from pathlib import Path
# Define a Worker Module
worker_module = Module(
Path("modules/worker.py"), # Path to the script defining the task
"fl-pytorch-mnist:latest", # Container image for task execution
maximum=4, # Maximum number of instances allowed
alias="worker", # Alias for referencing the module in the Swarm
method="any" # Execution method (e.g., any, all)
)
Key Parameters:
Path: Specifies the location of the script(s) defining the task.
Container Image: The Docker or similar image that encapsulates the task environment.
Maximum: The maximum number of instances that can be run for this module.
Alias: A short name used to identify the module within the Swarm.
Method: The execution method that defines how the module is scheduled (e.g., single execution or concurrent runs).
Modules constitue the backbone of the Swarm, allowing for the decomposition of complex algorithms into manageable, reusable, and scalable tasks that can be distributed across a network of devices.
Note
For more detailed information on implementing a Module class, refer to the Module API Documentation.
Example: Swarm Development¶
Federated Learning Overview¶
Federated Learning (FL) is a decentralized approach to training machine learning models where data remains on local devices, and only model updates are shared and aggregated. This process enhances privacy by keeping data on the nodes, making it particularly useful in sensitive applications like healthcare, finance, and mobile device personalization. For a deeper dive into federated learning concepts, refer to our detailed article on Federated Learning.
In the Manta platform, federated learning is implemented using a swarm of tasks distributed across multiple nodes, each contributing to a collaborative training process. The swarm’s pipeline typically includes workers, aggregators, and schedulers, as illustrated in the image below:
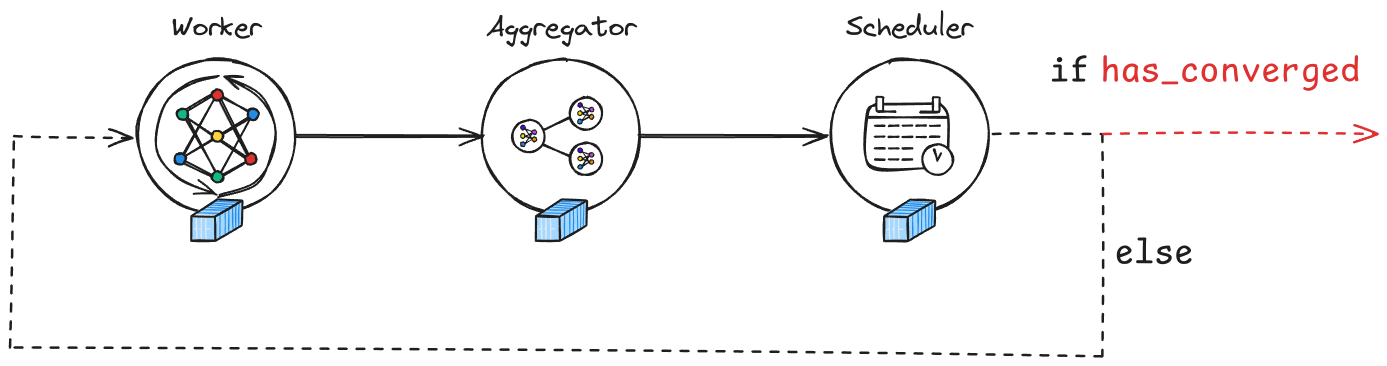
Swarm Structure:
Worker: Each worker node trains a model on local data and sends updates.
Aggregator: Aggregates the model updates from multiple workers.
Scheduler: Manages the workflow, checking for convergence and deciding when to terminate the swarm.
Defining a Federated Learning Swarm¶
Below is a code example that defines a federated learning swarm using the Manta platform. The FLSwarm class demonstrates how to set up the worker, aggregator, and scheduler modules.
from pathlib import Path
from manta.module import Module
from manta.swarm import Swarm
from manta_light.utils import numpy_to_bytes
from modules.worker.model import MLP
class FLSwarm(Swarm):
def __init__(self, n_workers: int = 4):
super().__init__()
# Define the Aggregator module, which combines updates from all workers
self.aggregator = Module(
Path("modules/aggregator.py"),
"fl-pytorch-mnist:latest", # Docker image used for the aggregator
method="any", # Execution method
fixed=False,
maximum=1, # Only one aggregator is used
alias="aggregator",
)
# Define the Worker module, which handles local model training
self.worker = Module(
Path("modules/worker"),
"fl-pytorch-mnist:latest", # Docker image used for workers
maximum=n_workers, # Number of worker nodes
alias="worker",
)
# Define the Scheduler module, which manages the swarm's iterations
self.scheduler = Module(
Path("modules/scheduler.py"),
"fl-pytorch-mnist:latest", # Docker image used for the scheduler
maximum=1,
alias="scheduler",
)
# Set global hyperparameters shared by all tasks in the swarm
self.set_global(
"hyperparameters",
{
"epochs": 1,
"batch_size": 32,
"loss": "CrossEntropyLoss",
"loss_params": {},
"optimizer": "SGD",
"optimizer_params": {"lr": 0.01, "momentum": 0.9},
},
)
# Initialize the global model parameters,
# converting them to bytes for transmission
self.set_global("global_model_params", numpy_to_bytes(MLP().get_weights()))
def execute(self):
"""
Define the execution flow of the swarm:
- Each iteration starts with the Worker.
- The results are then sent to the Aggregator.
- The Scheduler decides if the swarm should continue or stop based on convergence.
+--------+ +------------+ +-----------+ if has_converged
| Worker | --> | Aggregator | --> | Scheduler | ----------------> END PROGRAM
+--------+ +------------+ +-----------+
| | else
+--<<<----------<<<----------<<<----+
"""
m = self.worker() # Start with the worker task
m = self.aggregator(m) # Aggregate results from the workers
return self.scheduler(m) # Check for convergence or continue the loop