Developing a Task with manta-light¶
Tasks are the core building blocks of the decentralized algorithms in Manta. A Task defines the specific computations that are executed on each node in a Swarm. Using the manta-light API, tasks can interact with the node’s local data, access global parameters, and contribute results back to the shared context of the Swarm.
For more information, refer to the Task API Documentation.
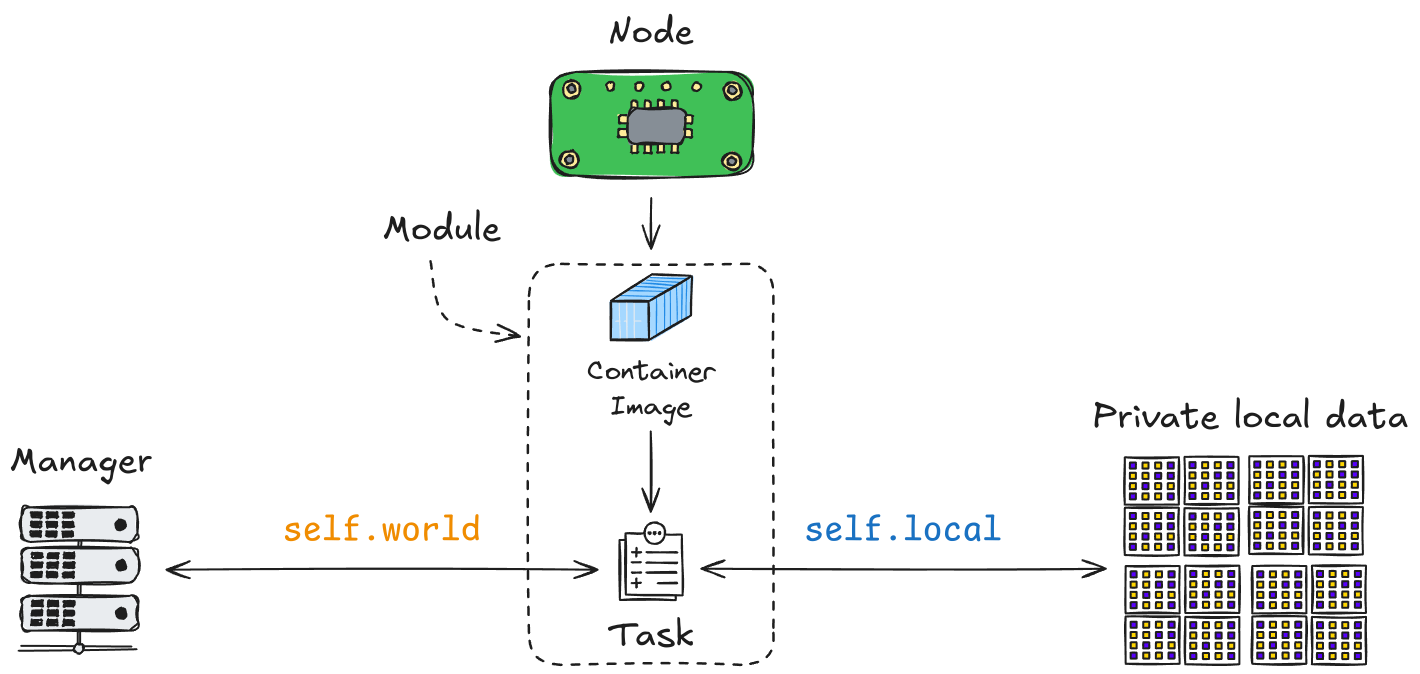
World, Globals, and Results¶
The manta-light API provides three main interfaces that are essential for task development: World, Globals, and Results.
Worldprovides the execution context for tasks. It allows tasks to interact with shared global variables (Globals) and store task-specific outputs (Results). TheWorldserves as the communication layer between tasks, making it possible to synchronize and share data across different nodes. For more details, refer to theWorldAPI Documentation.Globalsare global variables shared across all tasks and iterations within the Swarm. These variables can include parameters such as hyperparameters for training or other configuration settings that need to be accessible to all nodes. For more details, refer to theGlobalsAPI Documentation.Resultsallow tasks to store outputs that can be accessed in future iterations. For instance, model metrics, trained parameters, or intermediate results can be saved and used by subsequent tasks. For more details, refer to theResultsAPI Documentation.
Local API¶
The Local API provides tasks with access to the node’s local data. This data can include datasets for training, configuration files, or other resources that are stored locally on each node. The Local API abstracts the data storage mechanisms, allowing tasks to focus on processing the data rather than managing data retrieval.
Refer to the Local API Documentation for detailed information on interacting with local data.
Concrete Example: Federated Learning Swarm¶
The following examples demonstrate a set of tasks that form a simple Federated Learning Swarm. The swarm consists of three main tasks: Aggregator, Scheduler, and Worker. These tasks coordinate to train a shared model across multiple nodes without sharing the raw data, preserving privacy.
Worker Task (worker_task.py)¶
The Worker task trains a local model on the node’s data, evaluates it, and sends the results back to the global context.
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from manta_light.task import Task
from manta_light.utils import bytes_to_numpy, numpy_to_bytes
from .model import MLP
class Worker(Task):
def __init__(self):
super().__init__()
# Load MNIST dataset from local storage
raw_data = self.local.get_binary_data("mnist_part.npz")
self.data = np.load(raw_data)
self.model = MLP()
def run(self):
# Get model weights and hyperparameters from globals
weights = self.world.globals["global_model_params"]
self.model.set_weights(bytes_to_numpy(weights))
hyperparameters = self.world.globals["hyperparameters"]
# Train the model and collect metrics
metrics = self.train_model(hyperparameters)
# Save the metrics and model weights to the results
self.world.results.add("metrics", metrics)
self.world.results.add(
"model_params", numpy_to_bytes(self.model.get_weights())
)
def train_model(self, hyperparameters: dict):
"""
Trains the model using the given hyperparameters.
Parameters
----------
hyperparameters : dict
A dictionary containing training parameters like loss function,
optimizer, and epochs.
Returns
-------
dict
A dictionary with training metrics including loss and validation
accuracy.
"""
X_train, y_train, X_test, y_test = (
self.data["x_train"],
self.data["y_train"],
self.data["x_test"],
self.data["y_test"],
)
# Define loss function and optimizer
criterion = getattr(nn, hyperparameters["loss"])(
**hyperparameters.get("loss_params", {})
)
optimizer = getattr(optim, hyperparameters["optimizer"])(
self.model.parameters(), **hyperparameters.get("optimizer_params", {})
)
metrics = {"loss": [], "val_loss": [], "val_acc": []}
# Training loop
for epoch in range(hyperparameters["epochs"]):
self.model.train()
for i in range(0, X_train.shape[0], hyperparameters["batch_size"]):
optimizer.zero_grad()
output = self.model(
torch.tensor(X_train[i:i + hyperparameters["batch_size"]]).float()
)
loss = criterion(
output, torch.tensor(y_train[i:i + hyperparameters["batch_size"]])
)
loss.backward()
optimizer.step()
# Validation
self.model.eval()
with torch.no_grad():
val_output = self.model(torch.tensor(X_test).float())
val_loss = criterion(val_output, torch.tensor(y_test))
val_acc = (
(val_output.argmax(1) == torch.tensor(y_test)).float().mean().item()
)
metrics["loss"].append(loss.item())
metrics["val_loss"].append(val_loss.item())
metrics["val_acc"].append(val_acc)
return metrics
def main():
Worker().run()
Aggregator Task (aggregator.py)¶
The Aggregator task collects model parameters from all nodes, aggregates them, and updates the global model.
import numpy as np
from manta_light.task import Task
from manta_light.utils import bytes_to_numpy, numpy_to_bytes
class Aggregator(Task):
def run(self):
# Aggregate the models from all nodes
models = bytes_to_numpy(self.world.results.select("model_params"))
aggregated_model = self.aggregate_models(list(models.values()))
# Update the global model parameters
self.world.globals["global_model_params"] = numpy_to_bytes(aggregated_model)
def aggregate_models(self, models: list):
"""
Aggregates the given models by averaging their weights.
Parameters
----------
models : list
A list of model parameter dictionaries.
Returns
-------
dict
A dictionary representing the aggregated model parameters.
"""
aggregated_model = {}
for layer in models[0]:
aggregated_model[layer] = np.mean(
[model[layer] for model in models], axis=0
)
return aggregated_model
def main():
Aggregator().run()
Scheduler Task (scheduler.py)¶
The Scheduler task selects nodes for the next training iteration based on their validation accuracy and manages the Swarm’s scheduling logic.
from manta_light.task import Task
class Scheduler(Task):
def run(self):
# Select nodes based on validation accuracy metrics
metrics = self.world.results.select("metrics")
selected_nodes = self.select_nodes(metrics)
if selected_nodes:
self.world.schedule_next_iter(
node_ids=selected_nodes, task_to_schedule_alias="worker"
)
def select_nodes(self, metrics: dict):
"""
Selects nodes based on their validation accuracy.
Parameters
----------
metrics : dict
A dictionary containing metrics for each node.
Returns
-------
list
A list of node IDs that are selected for the next iteration.
"""
selected_nodes = []
val_acc_threshold = 0.95
for node_id, metr in metrics.items():
if metr["val_acc"][-1] < val_acc_threshold:
selected_nodes.append(node_id)
if not selected_nodes:
self.world.stop_swarm()
return selected_nodes
def main():
Scheduler().run()
This section provides a concrete example of how tasks interact with the local and global data within the Swarm, forming a complete federated learning loop that leverages the decentralized nature of the platform.