Développer une tâche avec manta-light¶
Les tâches sont les éléments de base des algorithmes décentralisés dans Manta. Une Task définit les calculs spécifiques exécutés sur chaque nœud d’un Swarm. En utilisant l’API manta-light, les tâches peuvent interagir avec les données locales du nœud, accéder aux paramètres globaux et contribuer aux résultats dans le contexte partagé du Swarm.
Pour plus d’informations, reportez-vous à la documentation de l’API Task.
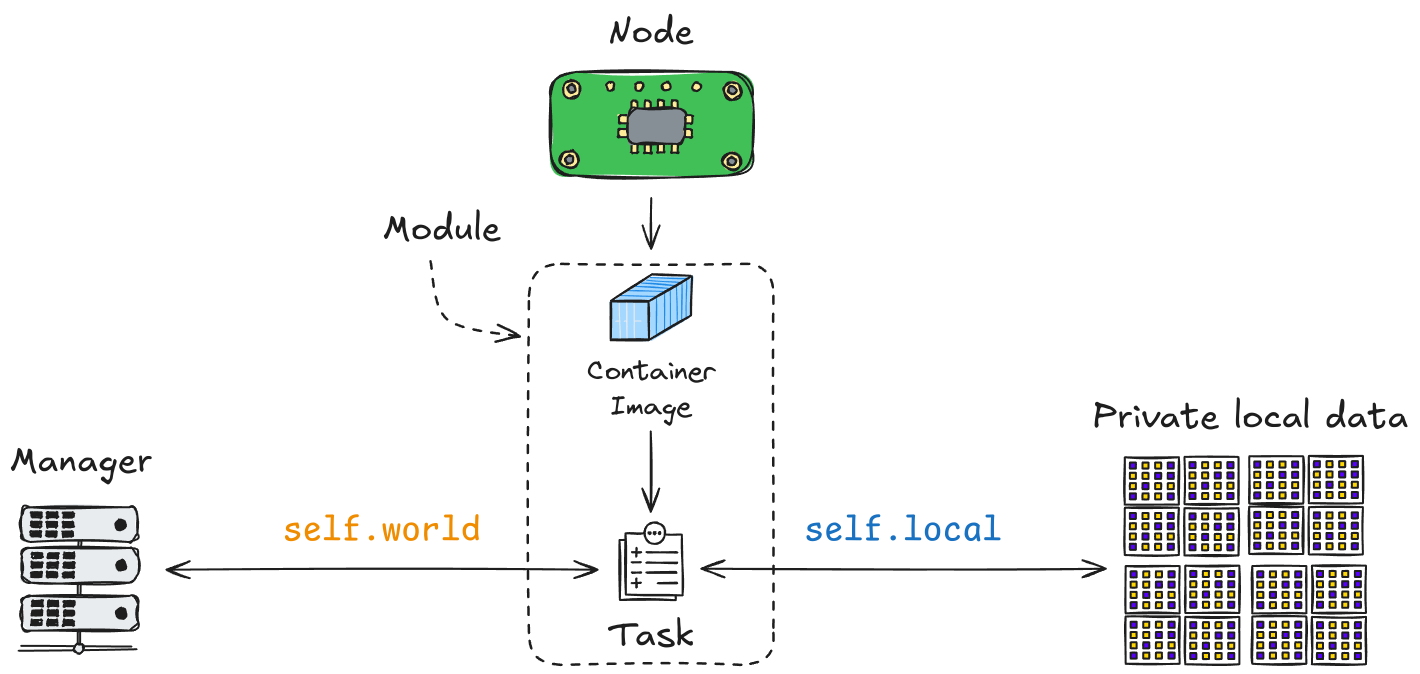
World, Globals et Results¶
L’API manta-light fournit trois interfaces principales essentielles pour le développement des tâches : World, Globals et Results.
Worldfournit le contexte d’exécution pour les tâches. Il permet aux tâches d’interagir avec des variables globales partagées (Globals) et de stocker les sorties spécifiques aux tâches (Results). LeWorldsert de couche de communication entre les tâches, permettant de synchroniser et de partager les données sur différents nœuds. Pour plus de détails, reportez-vous à la documentation de l’APIWorld.Globalssont des variables globales partagées entre toutes les tâches et itérations au sein d’un Swarm. Ces variables peuvent inclure des paramètres tels que des hyperparamètres pour l’entraînement ou d’autres paramètres de configuration qui doivent être accessibles à tous les nœuds. Pour plus de détails, reportez-vous à la documentation de l’APIGlobals.Resultspermet aux tâches de stocker des sorties accessibles dans les itérations futures. Par exemple, des métriques de modèle, des paramètres entraînés ou des résultats intermédiaires peuvent être enregistrés et utilisés par les tâches suivantes. Pour plus de détails, reportez-vous à la documentation de l’APIResults.
API locale¶
L’API locale fournit aux tâches un accès aux données locales du nœud. Ces données peuvent inclure des ensembles de données pour l’entraînement, des fichiers de configuration ou d’autres ressources stockées localement sur chaque nœud. L’API locale abstrait les mécanismes de stockage de données, permettant aux tâches de se concentrer sur le traitement des données plutôt que sur la gestion de leur récupération.
Reportez-vous à la documentation de l’API Local pour obtenir des informations détaillées sur l’interaction avec les données locales.
Exemple concret : Swarm d’apprentissage fédéré¶
Les exemples suivants démontrent un ensemble de tâches formant un Swarm d’apprentissage fédéré simple. Le Swarm se compose de trois tâches principales : Aggregator, Scheduler et Worker. Ces tâches se coordonnent pour entraîner un modèle partagé sur plusieurs nœuds sans partager les données brutes, préservant ainsi la confidentialité.
Tâche Worker (worker_task.py)¶
La tâche Worker entraîne un modèle local sur les données du nœud, l’évalue et renvoie les résultats au contexte global.
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from manta_light.task import Task
from manta_light.utils import bytes_to_numpy, numpy_to_bytes
from .model import MLP
class Worker(Task):
def __init__(self):
super().__init__()
# Load MNIST dataset from local storage
raw_data = self.local.get_binary_data("mnist_part.npz")
self.data = np.load(raw_data)
self.model = MLP()
def run(self):
# Get model weights and hyperparameters from globals
weights = self.world.globals["global_model_params"]
self.model.set_weights(bytes_to_numpy(weights))
hyperparameters = self.world.globals["hyperparameters"]
# Train the model and collect metrics
metrics = self.train_model(hyperparameters)
# Save the metrics and model weights to the results
self.world.results.add("metrics", metrics)
self.world.results.add(
"model_params", numpy_to_bytes(self.model.get_weights())
)
def train_model(self, hyperparameters: dict):
"""
Trains the model using the given hyperparameters.
Parameters
----------
hyperparameters : dict
A dictionary containing training parameters like loss function,
optimizer, and epochs.
Returns
-------
dict
A dictionary with training metrics including loss and validation
accuracy.
"""
X_train, y_train, X_test, y_test = (
self.data["x_train"],
self.data["y_train"],
self.data["x_test"],
self.data["y_test"],
)
# Define loss function and optimizer
criterion = getattr(nn, hyperparameters["loss"])(
**hyperparameters.get("loss_params", {})
)
optimizer = getattr(optim, hyperparameters["optimizer"])(
self.model.parameters(), **hyperparameters.get("optimizer_params", {})
)
metrics = {"loss": [], "val_loss": [], "val_acc": []}
# Training loop
for epoch in range(hyperparameters["epochs"]):
self.model.train()
for i in range(0, X_train.shape[0], hyperparameters["batch_size"]):
optimizer.zero_grad()
output = self.model(
torch.tensor(X_train[i:i + hyperparameters["batch_size"]]).float()
)
loss = criterion(
output, torch.tensor(y_train[i:i + hyperparameters["batch_size"]])
)
loss.backward()
optimizer.step()
# Validation
self.model.eval()
with torch.no_grad():
val_output = self.model(torch.tensor(X_test).float())
val_loss = criterion(val_output, torch.tensor(y_test))
val_acc = (
(val_output.argmax(1) == torch.tensor(y_test)).float().mean().item()
)
metrics["loss"].append(loss.item())
metrics["val_loss"].append(val_loss.item())
metrics["val_acc"].append(val_acc)
return metrics
def main():
Worker().run()
Tâche Aggregator (aggregator.py)¶
La tâche Aggregator collecte les paramètres du modèle provenant de tous les nœuds, les agrège et met à jour le modèle global.
import numpy as np
from manta_light.task import Task
from manta_light.utils import bytes_to_numpy, numpy_to_bytes
class Aggregator(Task):
def run(self):
# Aggregate the models from all nodes
models = bytes_to_numpy(self.world.results.select("model_params"))
aggregated_model = self.aggregate_models(list(models.values()))
# Update the global model parameters
self.world.globals["global_model_params"] = numpy_to_bytes(aggregated_model)
def aggregate_models(self, models: list):
"""
Aggregates the given models by averaging their weights.
Parameters
----------
models : list
A list of model parameter dictionaries.
Returns
-------
dict
A dictionary representing the aggregated model parameters.
"""
aggregated_model = {}
for layer in models[0]:
aggregated_model[layer] = np.mean(
[model[layer] for model in models], axis=0
)
return aggregated_model
def main():
Aggregator().run()
Tâche Scheduler (scheduler.py)¶
La tâche Scheduler sélectionne les nœuds pour la prochaine itération d’entraînement en fonction de leur précision de validation et gère la logique de planification du Swarm.
from manta_light.task import Task
class Scheduler(Task):
def run(self):
# Select nodes based on validation accuracy metrics
metrics = self.world.results.select("metrics")
selected_nodes = self.select_nodes(metrics)
if selected_nodes:
self.world.schedule_next_iter(
node_ids=selected_nodes, task_to_schedule_alias="worker"
)
def select_nodes(self, metrics: dict):
"""
Selects nodes based on their validation accuracy.
Parameters
----------
metrics : dict
A dictionary containing metrics for each node.
Returns
-------
list
A list of node IDs that are selected for the next iteration.
"""
selected_nodes = []
val_acc_threshold = 0.95
for node_id, metr in metrics.items():
if metr["val_acc"][-1] < val_acc_threshold:
selected_nodes.append(node_id)
if not selected_nodes:
self.world.stop_swarm()
return selected_nodes
def main():
Scheduler().run()
Cette section fournit un exemple concret de la façon dont les tâches interagissent avec les données locales et globales au sein du Swarm, formant une boucle complète d’apprentissage fédéré qui exploite la nature décentralisée de la plateforme.