Développement d’un Swarm¶
Introduction¶
Dans la plateforme Manta, le développement Swarm permet aux utilisateurs de créer algorithmes décentralisés et collaboratifs qui sont distribués à travers plusieurs nœuds. Un Swarm se compose de diverses tâches définies par le utilisateur, qui sont exécutés de manière collaborative sur les nœuds. Le noyau Manta fournit les outils et abstractions nécessaires pour développer, déployer et surveiller efficacement ces Swarms, permettant une exécution transparente de tâches complexes, flux de travail distribués.
Qu’est-ce qu’un Swarm ?¶
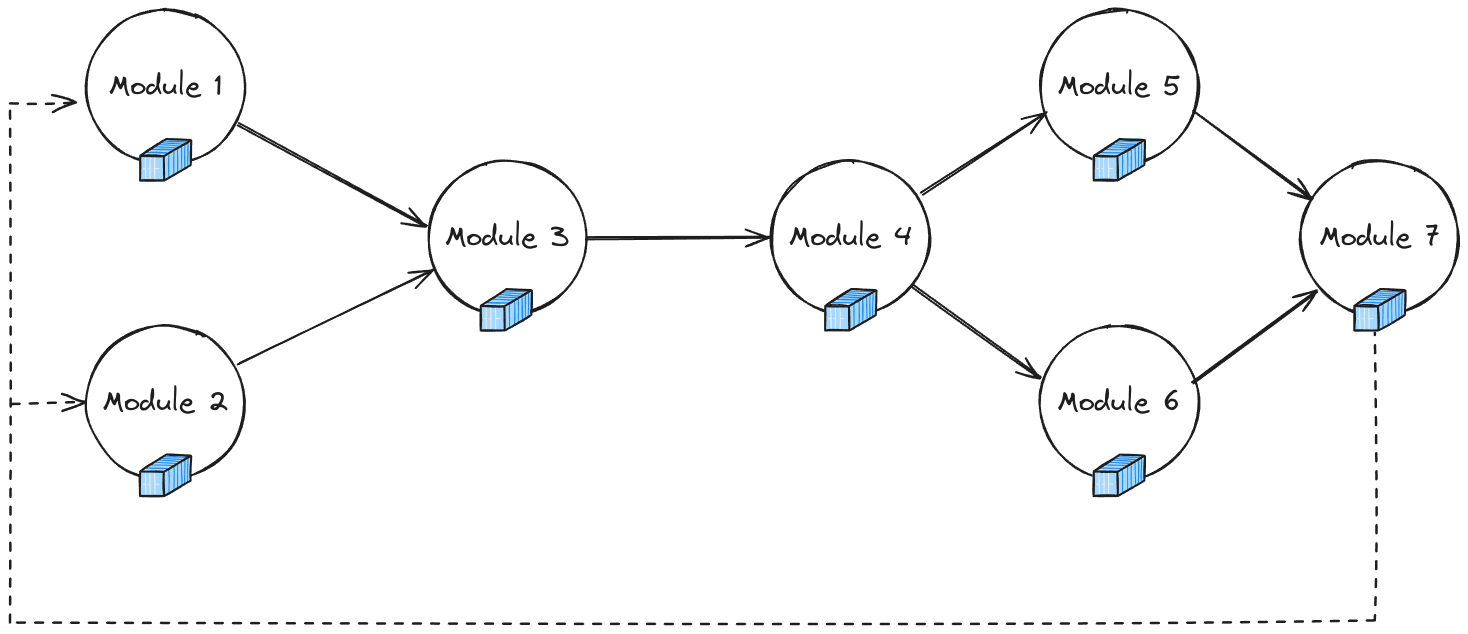
Un Swarm est un pipeline décentralisé composé de tâches interconnectées qui s’exécutent de manière collaborative sur plusieurs nœuds dans un système distribué. Chaque swarm définit une séquence d’opérations, organisées en tâches, qui exécuter collectivement un algorithme plus vaste. La principale caractéristique d’un Swarm est sa capacité à définir une itération qui se répète jusqu’à un certain point condition ou les critères d’achèvement sont remplis. Cette approche itérative permet pour un traitement continu des données et un affinement à travers plusieurs étapes.
Composants d’un Swarm :
Tâches : Les éléments de base d’un Swarm, chaque tâche exécute une opération ou calcul spécifique. Les tâches peuvent dépendre les unes des autres, permettant de construire des workflows complexes.
Dépendances : Les tâches au sein d’un Swarm peuvent être interconnectées via des dépendances définies, créant un graphe orienté d’opérations. Ces les dépendances contrôlent le flux de données et l’ordre d’exécution entre les tâches.
Cycle d’itération : Un Swarm est conçu pour fonctionner par cycles, où le les tâches définies sont exécutées de manière répétée jusqu’à ce que le Swarm termine son objectif.
Comment fonctionnent les Swarms¶
Les Swarms fonctionnent en définissant un flux de travail itératif qui est distribué sur plusieurs nœuds. À chaque itération, les tâches traitent les données, communiquent avec d’autres tâches et contribuer à la progression globale de le Swarm. Cette configuration est particulièrement utile pour les algorithmes collaboratifs, où les nœuds doivent travailler ensemble pour atteindre un objectif commun.
Le diagramme ci-dessus illustre un Swarm composé de quatre tâches répartis sur plusieurs nœuds. Les tâches communiquent entre elles pour transmettre données et synchroniser leurs opérations. Après avoir terminé un cycle, le Le Swarm passe à l’itération suivante jusqu’à ce qu’il atteigne la terminaison condition.
Classe Swarm¶
Pour créer un nouveau Swarm, vous définissez une classe Python qui hérite de la manta.swarm.Swarm classe de base. Cette classe personnalisée spécifie le tâches, leurs dépendances et la structure globale du système décentralisé algorithme.
Pour des informations plus détaillées sur l’implémentation d’une classe Swarm, reportez-vous à la Documentation de l’API Swarm.
Module Classe¶
Module définit une tâche au sein de le Swarm et sert de bloc de construction à tout algorithme décentralisé. Chaque module représente une tâche individuelle qui fonctionne de manière indépendante, exécutant calculs basés sur les données locales du nœud et contribuant à la processus global de Swarm. Les modules sont exécutés dans le conteneur environnements, permettant des déploiements isolés, reproductibles et évolutifs sur des appareils hétérogènes, des serveurs haute puissance aux appareils de pointe.
Fonctionnalités principales d’un module :
Exécution conteneurisée : Chaque module spécifie une image de conteneur (par exemple, Docker) qui encapsule l’environnement de la tâche, garantissant cohérence entre les différents nœuds.
Indépendance des tâches : les modules sont autonomes, ce qui signifie qu’ils peuvent fonctionner sans dépendances sur d’autres modules, à l’exception de ceux définis voies de communication ou d’échange de données.
Création d’un module:
Pour définir un module, vous créez une instance du Module classe, spécifiant le script ou l’ensemble de scripts qui forment la tâche, l’environnement du conteneur et diverses exécutions paramètres. Vous trouverez ci-dessous un exemple de définition d’un module :
from manta.module import Module
from pathlib import Path
# Define a Worker Module
worker_module = Module(
Path("modules/worker.py"), # Path to the script defining the task
"fl-pytorch-mnist:latest", # Container image for task execution
maximum=4, # Maximum number of instances allowed
alias="worker", # Alias for referencing the module in the Swarm
method="any" # Execution method (e.g., any, all)
)
Paramètres clés:
Chemin : spécifie l’emplacement du ou des scripts définissant la tâche.
Image du conteneur : l’image Docker ou similaire qui encapsule l’environnement de tâche.
Maximum : le nombre maximal d’instances pouvant être exécutées pour celamodule.
Alias : un nom court utilisé pour identifier le module au sein du Swarm.
Méthode : La méthode d’exécution qui définit la manière dont le module est planifié(par exemple, exécution unique ou exécutions simultanées).
Les modules constituent l’épine dorsale du Swarm, permettant ladécomposition d’algorithmes complexes en algorithmes gérables, réutilisables ettâches évolutives pouvant être distribuées sur un réseau d’appareils.
Note
Pour des informations plus détaillées sur l’implémentation d’une classe Module, reportez-vous à la documentation de l’API Module.
Exemple : Développement d’un Swarm¶
Présentation de l’apprentissage fédéré¶
L’apprentissage fédéré (FL) est une approche décentralisée de la formation des machines.modèles d’apprentissage où les données restent sur les appareils locaux et uniquement sur le modèle les mises à jour sont partagées et agrégées. Ce processus améliore la confidentialité en conserver les données sur les nœuds, ce qui le rend particulièrement utile dans les cas sensibles des applications telles que les soins de santé, la finance et la personnalisation des appareils mobiles. Pour une analyse plus approfondie des concepts d’apprentissage fédéré, reportez-vous à notre article détaillé sur l”apprentissage fédéré.
Dans la plateforme Manta, l’apprentissage fédéré est mis en œuvre à l’aide d’un Swarm de tâches réparties sur plusieurs nœuds, chacun contribuant à un processus de formation collaborative. Le pipeline du Swarm comprend généralement travailleurs, agrégateurs et planificateurs, comme illustré dans l’image ci-dessous :
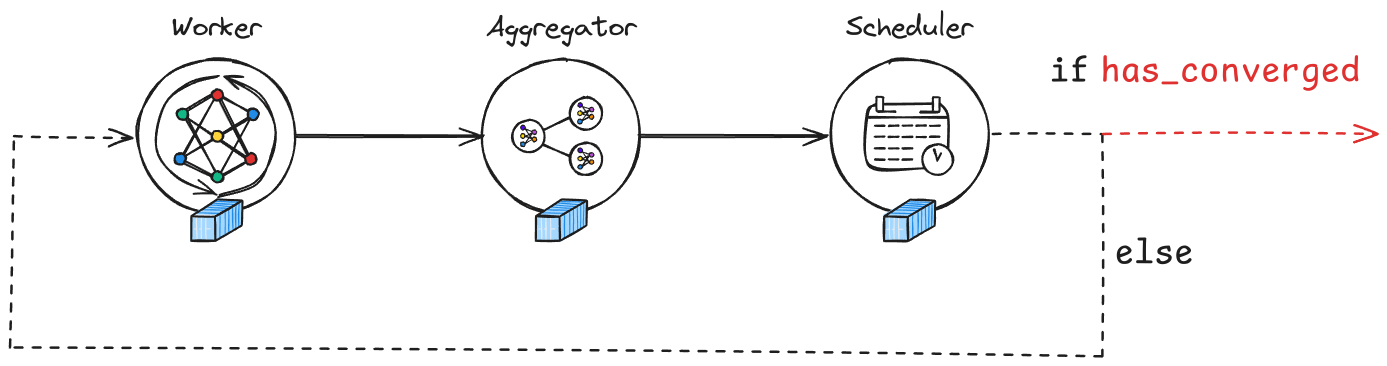
Structure d’un Swarm :
Worker : chaque nœud de travail entraîne un modèle sur des données locales et envoie mises à jour.
Agrégateur : regroupe les mises à jour du modèle provenant de plusieurs travailleurs.
Planificateur : gère le flux de travail, vérifie la convergence et décider quand mettre fin au Swarm.
Définition d’un Swarm d’apprentissage fédéré¶
Vous trouverez ci-dessous un exemple de code qui définit un Swarm d’apprentissage fédéré à l’aide de Plateforme Manta. La classe FLSwarm montre comment configurer la modules de travail, d’agrégation et de planification.
from pathlib import Path
from manta.module import Module
from manta.swarm import Swarm
from manta_light.utils import numpy_to_bytes
from modules.worker.model import MLP
class FLSwarm(Swarm):
def __init__(self, n_workers: int = 4):
super().__init__()
# Define the Aggregator module, which combines updates from all workers
self.aggregator = Module(
Path("modules/aggregator.py"),
"fl-pytorch-mnist:latest", # Docker image used for the aggregator
method="any", # Execution method
fixed=False,
maximum=1, # Only one aggregator is used
alias="aggregator",
)
# Define the Worker module, which handles local model training
self.worker = Module(
Path("modules/worker"),
"fl-pytorch-mnist:latest", # Docker image used for workers
maximum=n_workers, # Number of worker nodes
alias="worker",
)
# Define the Scheduler module, which manages the swarm's iterations
self.scheduler = Module(
Path("modules/scheduler.py"),
"fl-pytorch-mnist:latest", # Docker image used for the scheduler
maximum=1,
alias="scheduler",
)
# Set global hyperparameters shared by all tasks in the swarm
self.set_global(
"hyperparameters",
{
"epochs": 1,
"batch_size": 32,
"loss": "CrossEntropyLoss",
"loss_params": {},
"optimizer": "SGD",
"optimizer_params": {"lr": 0.01, "momentum": 0.9},
},
)
# Initialize the global model parameters,
# converting them to bytes for transmission
self.set_global("global_model_params", numpy_to_bytes(MLP().get_weights()))
def execute(self):
"""
Define the execution flow of the swarm:
- Each iteration starts with the Worker.
- The results are then sent to the Aggregator.
- The Scheduler decides if the swarm should continue or stop based on convergence.
+--------+ +------------+ +-----------+ if has_converged
| Worker | --> | Aggregator | --> | Scheduler | ----------------> END PROGRAM
+--------+ +------------+ +-----------+
| | else
+--<<<----------<<<----------<<<----+
"""
m = self.worker() # Start with the worker task
m = self.aggregator(m) # Aggregate results from the workers
return self.scheduler(m) # Check for convergence or continue the loop